Revolutionizing Language Models
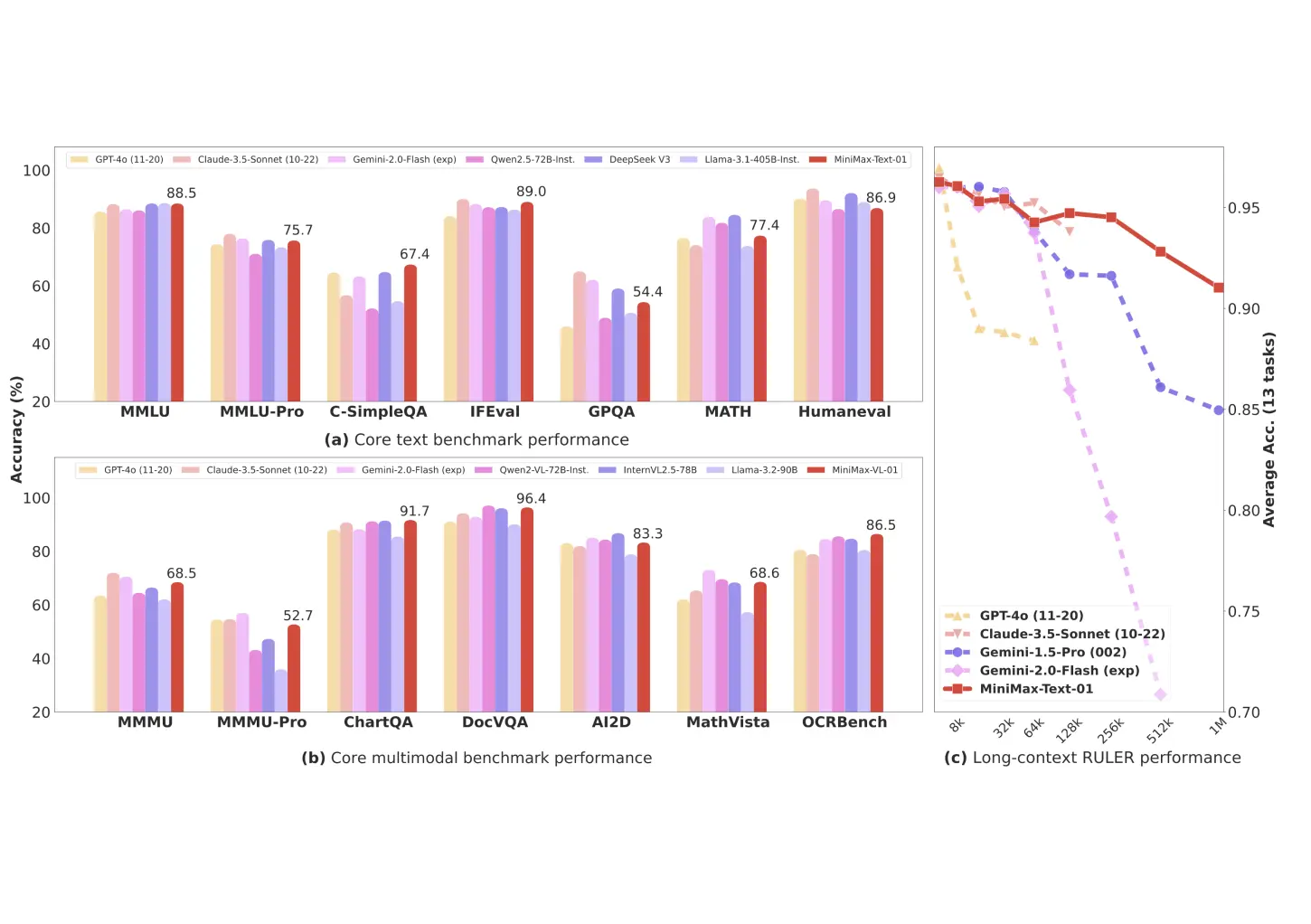
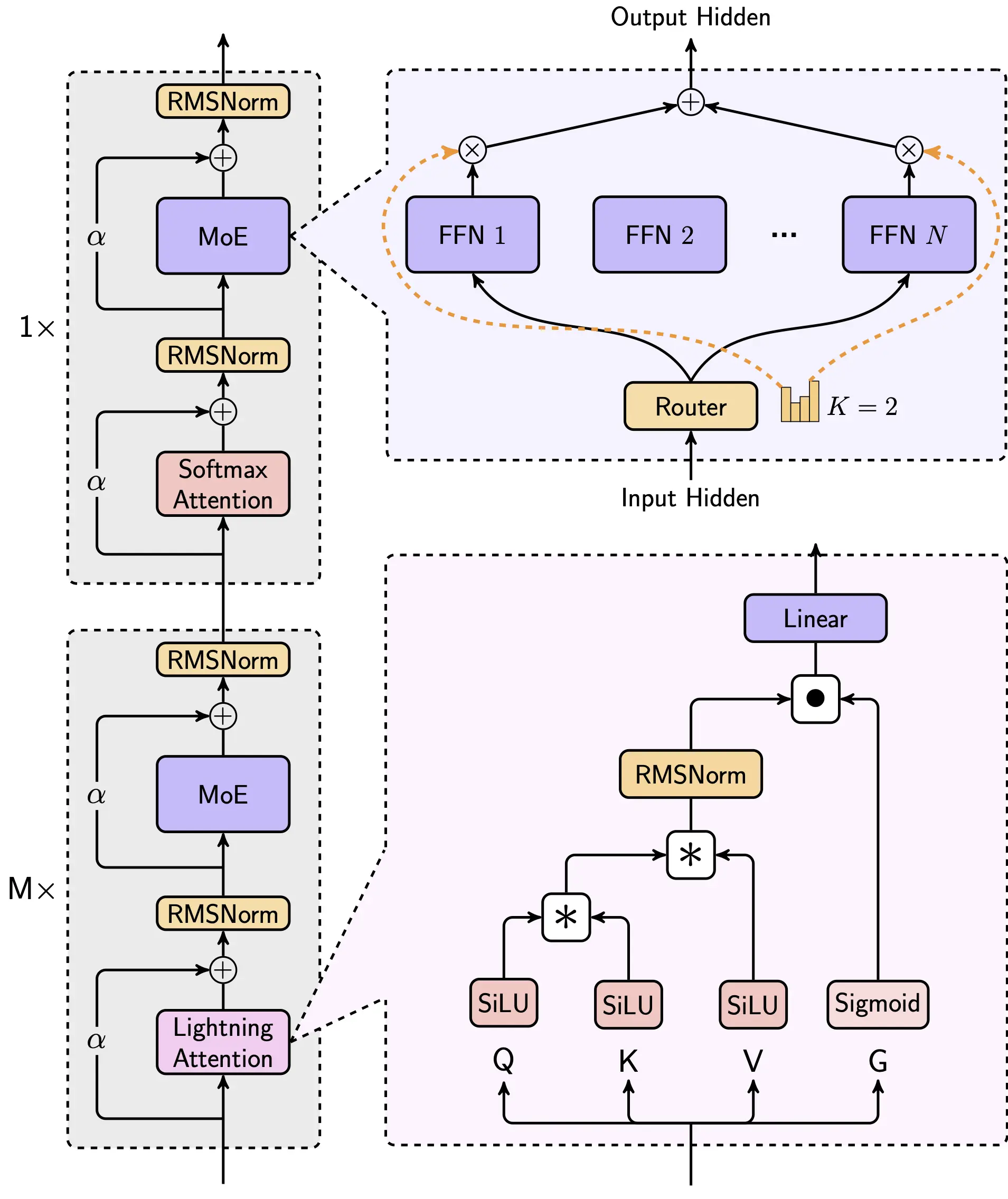
MiniMax-VL-01: A groundbreaking 456B parameter language model with innovative hybrid architecture, processing up to 4 million tokens of context - 32x more than GPT-4.
MiniMax-VL-01 is a powerful language model that supports multiple intelligent conversation scenarios, making your applications smarter.

Aleeyah
5.0